
## 一、项目介绍
这是一个超简单的Python爬虫入门示例,专门给零基础的小白准备的。只需要几十行代码,就能学会爬取网页上的内容,保存到本地文件。
**功能特点:**
– 零基础也能学会,步骤超详细
– 只用两个第三方库,安装简单
– 爬取网页标题和链接,实用又好懂
– 结果保存到txt文件,方便查看
– 代码注释详细,每一行都讲明白
**适合人群:**
– 刚学Python的新手
– 对爬虫感兴趣的小白
– 想做简单数据采集的同学
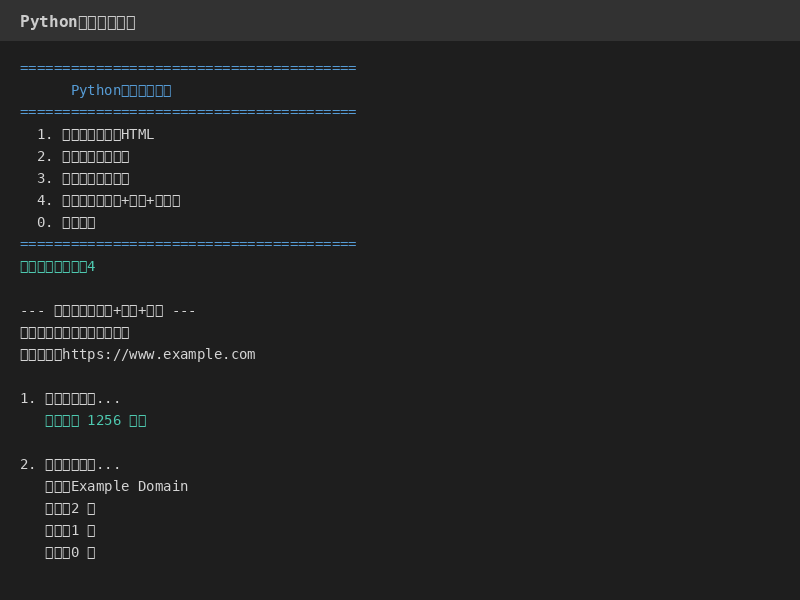
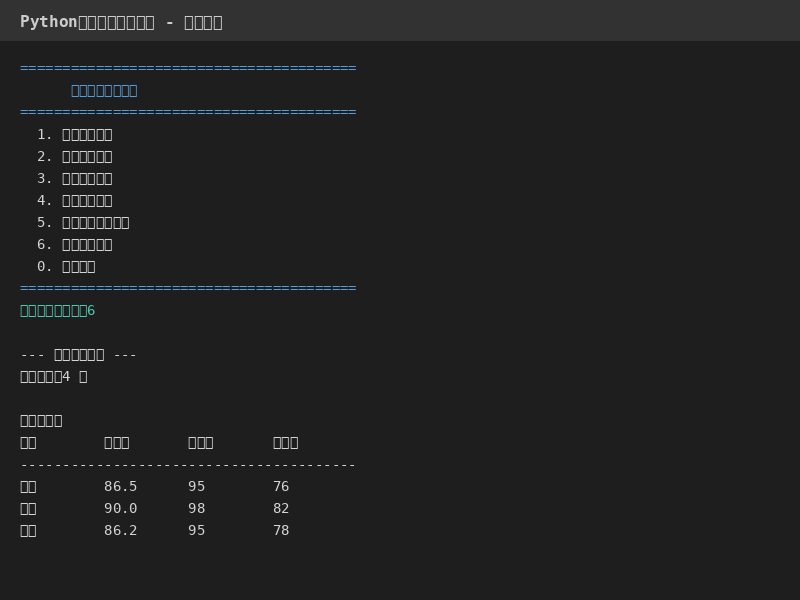
## 二、效果展示

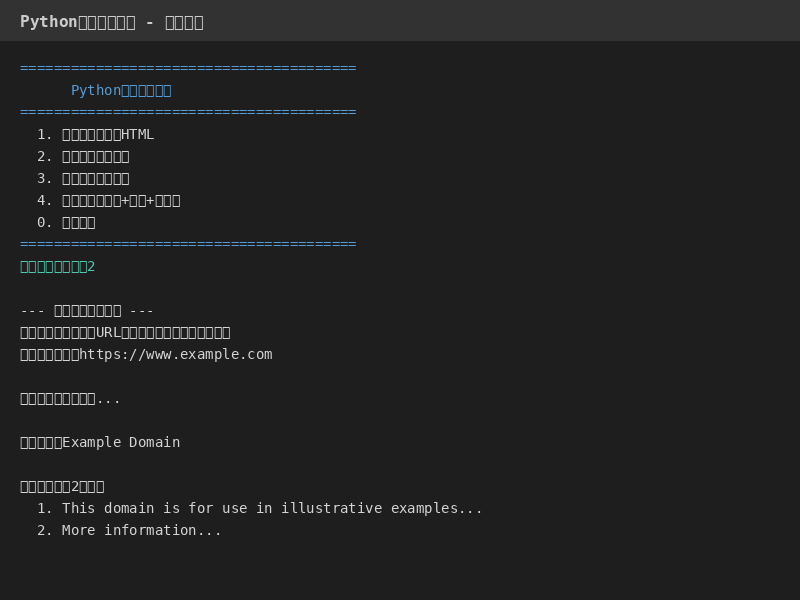
## 三、小白教程
### 第一步:安装Python
如果你还没装Python,先去官网下载安装:
1. 打开浏览器,访问 python.org
2. 点击 Downloads 下载最新版Python
3. 安装时一定要勾选”Add Python to PATH”(把Python添加到环境变量)
4. 一路点Next安装完成
安装完成后,按Win+R输入cmd打开命令提示符,输入python –version,如果显示版本号就说明装好了。
### 第二步:安装需要的库
这个爬虫只需要两个第三方库,打开命令提示符,输入下面两条命令安装:
“`
pip install requests
pip install beautifulsoup4
“`
每条命令输完按回车,等待安装完成。如果下载慢,可以用国内镜像源:
“`
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
“`
### 第三步:创建Python文件
1. 在桌面上新建一个文件夹,叫”爬虫示例”
2. 打开文件夹,右键新建文本文档
3. 把文件名改成”crawler.py”(注意后缀名要从.txt改成.py)
4. 如果看不到后缀名,点文件夹上方的”查看”,勾选”文件扩展名”
### 第四步:复制代码
右键点击crawler.py,选择用记事本打开(或者用VS Code、PyCharm等编辑器),把下面的完整源码复制进去,保存文件。
### 第五步:运行程序
1. 在爬虫示例文件夹的地址栏输入cmd,按回车,打开命令提示符
2. 输入 python crawler.py 按回车运行
3. 程序会自动爬取网页内容,保存到result.txt文件
4. 运行完成后,文件夹里会多出一个result.txt,就是爬取的结果
### 常见问题
**Q:运行提示找不到模块?**
A:说明库没装好,重新执行第二步的安装命令,确保网络通畅。
**Q:爬取失败?**
A:可能是目标网站反爬了,可以换个简单的网站试试,比如example.com。
**Q:中文显示乱码?**
A:代码里加一行encoding=’utf-8’,保存文件时也选UTF-8编码。
## 四、完整源码
# 导入需要的库
import requests
from bs4 import BeautifulSoup
# 目标网址(这里用example.com做示例,简单稳定)
url = "https://www.example.com"
# 设置请求头,模拟浏览器访问,防止被反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
try:
# 发送GET请求,获取网页内容
print("正在发送请求...")
response = requests.get(url, headers=headers)
response.encoding = "utf-8" # 设置编码,防止中文乱码
# 检查请求是否成功
if response.status_code == 200:
print("请求成功!")
# 用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, "html.parser")
# 提取网页标题
title = soup.title.string
print(f"网页标题:{title}")
# 提取所有链接
links = soup.find_all("a")
print(f"找到 {len(links)} 个链接:")
# 保存结果到文件
with open("result.txt", "w", encoding="utf-8") as f:
f.write(f"网页标题:{title}\n")
f.write("=" * 50 + "\n")
f.write("所有链接:\n\n")
for i, link in enumerate(links, 1):
link_text = link.get_text(strip=True)
link_href = link.get("href", "")
print(f"{i}. {link_text} -> {link_href}")
f.write(f"{i}. {link_text} -> {link_href}\n")
print("\n" + "=" * 50)
print("结果已保存到 result.txt 文件!")
else:
print(f"请求失败,状态码:{response.status_code}")
except Exception as e:
print(f"出错了:{e}")
print("请检查网络连接,或者换个网址试试")



暂无评论内容